
在图的遍历中,常用的两种算法是深度优先遍历(DFS)和广度优先遍历(BFS)。邻接表是表示图的一种方式,通常用于存储稀疏图。
一、 深度优先遍历次序(DFS)
深度优先遍历(DFS)是从一个顶点开始,沿着图的边深入,直到无法继续为止,然后回溯到最近的一个分支点,继续遍历未访问的顶点。
算法步骤:
- 从图的一个起始节点出发,访问该节点并标记为已访问。
- 对于当前节点的每个邻接节点,若该邻接节点未被访问,则递归地访问该节点。
- 遍历完成后,回溯到上一个节点,直到所有可访问的节点都被访问过。
DFS的次序:访问节点的顺序即为深度优先遍历次序。通常情况下,使用递归或栈来实现。
计算方法:
- 以邻接表为例,对于一个节点,访问它的所有邻接节点,并按某种顺序(例如按照节点编号、字母顺序等)递归地进行遍历。
- 一旦遍历完成后,返回到上一个节点,继续遍历其他邻接节点。
二、 深度优先遍历生成树
深度优先遍历生成树是通过深度优先遍历算法从某一根节点开始构建的一棵树。树的结构由所有访问过的节点构成。
生成树的计算方法:
- 每次递归到一个新的未被访问的节点时,该节点与上一个访问的节点之间就形成一条边,构成树中的一条边。
- 如果一个节点的某个邻接节点已经被访问过,则不再生成边。
三、 广度优先遍历次序(BFS)
广度优先遍历(BFS)是从一个起始节点开始,访问该节点,并且依次访问与当前节点距离为1、2、3…的节点,直到所有可达节点都被访问。
算法步骤:
- 从图的一个起始节点开始,访问该节点并标记为已访问。
- 将该节点的所有未被访问的邻接节点加入队列。
- 从队列中取出一个节点,访问它,并将它的所有未被访问的邻接节点加入队列。
- 重复步骤3,直到队列为空。
BFS的次序:访问节点的顺序即为广度优先遍历次序。通常使用队列来实现。
计算方法:
- 以邻接表为例,从起始节点开始,首先访问该节点并将其邻接节点按顺序加入队列。
- 然后依次取出队列中的节点,访问这些节点,并将它们的邻接节点按顺序加入队列,直到所有节点都被访问。
四、 广度优先遍历生成树
广度优先遍历生成树是通过广度优先遍历算法从某一根节点开始构建的一棵树。
生成树的计算方法:
- 当从一个节点访问其邻接节点时,若该邻接节点尚未访问过,便将该节点与当前节点之间的边加入生成树。
- 广度优先遍历的过程中,当访问到一个节点时,它的父节点就是第一个从队列中取出的节点。
示例说明
假设有一个图G,包含以下邻接表:
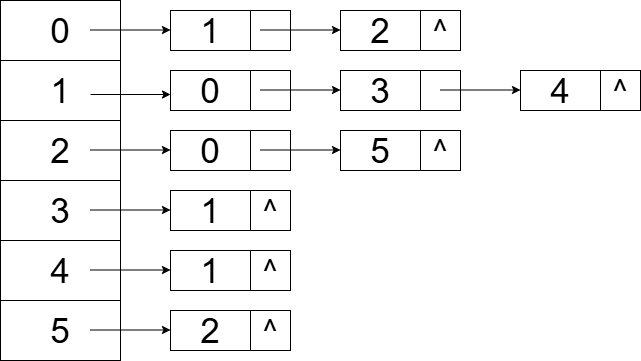
1. DFS遍历
- 从节点
0开始,DFS的遍历次序可能是:0 -> 1 -> 3 -> 4 -> 2 -> 5 - 生成树:边为
(0, 1), (1, 3), (1, 4), (0, 2), (2, 5)
2. BFS遍历
- 从节点
0开始,BFS的遍历次序可能是:0 -> 1 -> 2 -> 3 -> 4 -> 5 - 生成树:边为
(0, 1), (0, 2), (1, 3), (1, 4), (2, 5)
评论留言
欢迎您,!您可以在这里畅言您的的观点与见解!
0 条评论